Clustered Index
A clustered index defines the order in which data is physically stored in a table. Table data can be sorted in only way, therefore, there can be only one clustered index per table. In SQL Server, the primary key constraint automatically creates a clustered index on that particular column.
CREATE DATABASE schooldb
CREATE TABLE student (
id INT PRIMARY KEY, -- <==
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
DOB datetime NOT NULL,
total_score INT NOT NULL,
city VARCHAR(50) NOT NULL
)
--------------------------------
USE schooldb
EXECUTE sp_helpindex student
The above query will return this result:

USE schooldb
INSERT INTO student
VALUES
(6, 'Kate', 'Female', '03-JAN-1985', 500, 'Liverpool'),
(2, 'Jon', 'Male', '02-FEB-1974', 545, 'Manchester'),
(9, 'Wise', 'Male', '11-NOV-1987', 499, 'Manchester'),
(3, 'Sara', 'Female', '07-MAR-1988', 600, 'Leeds'),
(1, 'Jolly', 'Female', '12-JUN-1989', 500, 'London'),
(4, 'Laura', 'Female', '22-DEC-1981', 400, 'Liverpool'),
(7, 'Joseph', 'Male', '09-APR-1982', 643, 'London'),
(5, 'Alan', 'Male', '29-JUL-1993', 500, 'London'),
(8, 'Mice', 'Male', '16-AUG-1974', 543, 'Liverpool'),
(10, 'Elis', 'Female', '28-OCT-1990', 400, 'Leeds');
-- NOTE id's in random order upon insertion
--------------------------------
USE schooldb
SELECT * FROM student
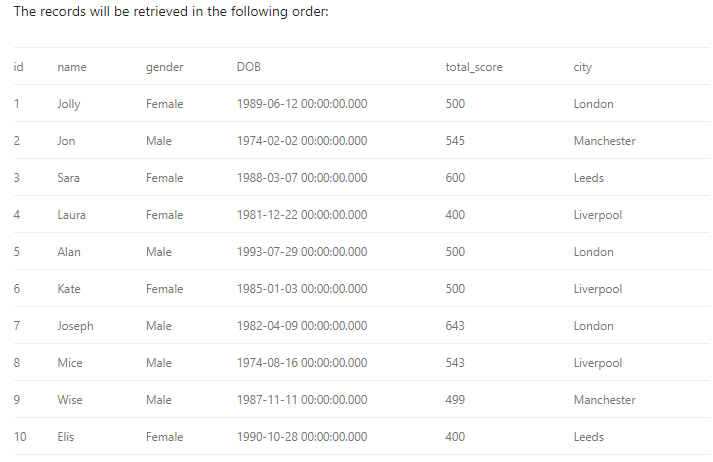
Creating a new Clustered index:
-- Since there can only be 1 per table, you'll need to delete the original one on the Primary Key
use schooldb
CREATE CLUSTERED INDEX IX_tblStudent_Gender_Score
ON student(gender ASC, total_score DESC)
The characteristics of the best clustering keys can be summarized in few points that are followed by most of the designers:
Short: Although SQL Server allows us to add up to 16 columns to the clustered index key, with maximum key size of 900 bytes, the typical clustered index key is much smaller than what is allowed, with as few columns as possible. The wide Clustered index key will also affect all non-clustered indexes built over that clustered index, as the clustered index key will be used as a lookup key for all the non-clustered indexes pointing to it. Static: It is recommended to choose the columns that are not changed frequently in the clustered index key. Changing the clustered index key values means that the whole row will be moved to the new proper page to keep the data values in the correct order. Increasing: Using an increasing column, such as the IDENTITY column, as a clustered index key will help in improving the INSERT process, that will directly insert the new values at the logical end of the table. This highly recommended choice will help in reducing the amount of memory required for the page buffers, minimize the need to split the page into two pages to fit the newly inserted values and the fragmentation occurrence, that required rebuilding or reorganizing the index again. Unique: It is recommended to declare the clustered index key column or combination of columns as unique to improve the queries performance. Otherwise, SQL Server will automatically add a uniqueifier column to enforce the clustered index key uniqueness. Accessed frequently: This is due to the fact that the rows will be stored in the clustered index in a sorted order based on that index key that is used to access the data. Used in the ORDER BY clause: In this case, no need for the SQL Server Engine to sort the data in order to display it, as the rows are already sorted based on the index key used in the ORDER BY clause.
- Reference:
Backlinks