Write Data This Alternative Is 7 Times Faster
Author:dario-radečićLink:https://towardsdatascience.com/stop-using-pandas-to-read-write-data-this-alternative-is-7-times-faster-893301633475Publish Date:2021-10-22Reviewed Date:01
- Pyarrow for faster data reads
pip install pyarrow
- video format of this article https://youtu.be/gFd4I1oXG8E
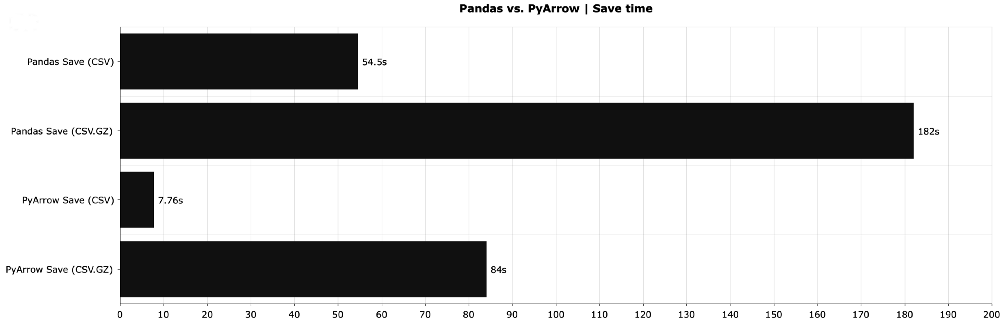
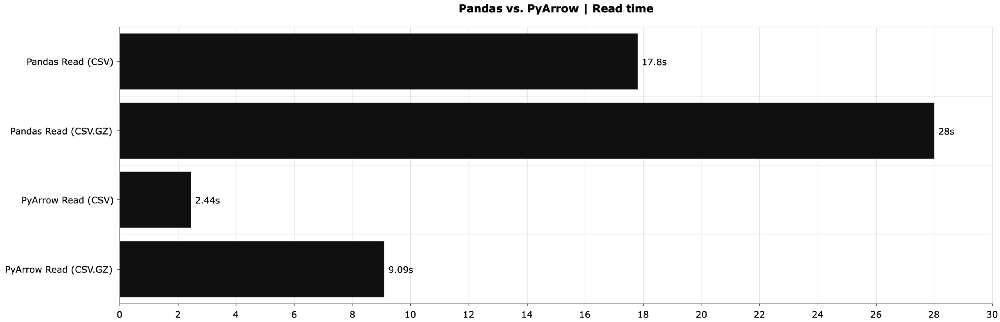
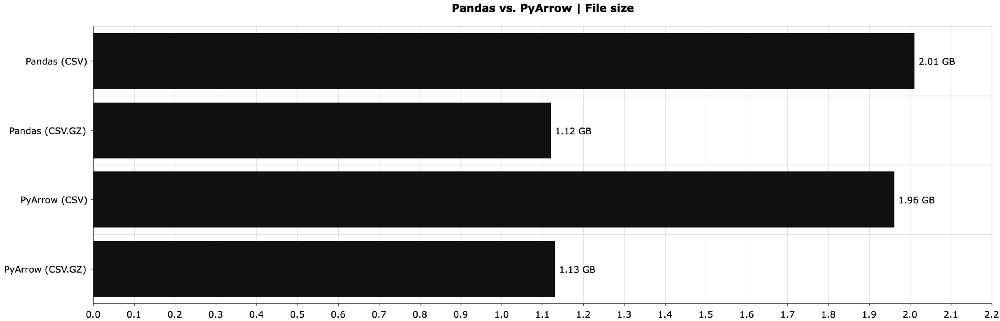
# Create a dummy dataset:
import random
import string
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.csv as csv
from datetime import datetime
def gen_random_string(length: int = 32) -> str:
return ''.join(random.choices(
string.ascii_uppercase + string.digits, k=length)
)
dt = pd.date_range(
start=datetime(2000, 1, 1),
end=datetime(2021, 1, 1),
freq='min'
)
np.random.seed = 42
df_size = len(dt)
print(f'Dataset length: {df_size}')
df = pd.DataFrame({
'date': dt,
'a': np.random.rand(df_size),
'b': np.random.rand(df_size),
'c': np.random.rand(df_size),
'd': np.random.rand(df_size),
'e': np.random.rand(df_size),
'str1': [gen_random_string() for x in range(df_size)],
'str2': [gen_random_string() for x in range(df_size)]
})
# 1 test baseline speed of pandas
## even being kind by using the compression parameter
df.to_csv('csv_pandas.csv.gz', index=False, compression='gzip')
# Check read times
df1 = pd.read_csv('csv_pandas.csv')
# **NOTE:** Here’s a thing you should know about PyArrow — it can’t handle datetime columns. You’ll have to convert the date attribute to a timestamp. Here’s how:
df_pa = df.copy()
df_pa['date'] = df_pa['date'].values.astype(np.int64) // 10 ** 9
df_pa_table = pa.Table.from_pandas(df_pa)
csv.write_csv(df_pa_table, 'csv_pyarrow.csv')
# Adding compression
with pa.CompressedOutputStream('csv_pyarrow.csv.gz', 'gzip') as out:
csv.write_csv(df_pa_table, out)
# You can read both compressed and uncompressed dataset with the csv.read_csv() function:
df_pa_1 = csv.read_csv('csv_pyarrow.csv')
df_pa_2 = csv.read_csv('csv_pyarrow.csv.gz')
# Both will be read in the pyarrow.Table format, so use the following command to convert them to a Pandas DataFrame:
df_pa_1 = df_pa_1.to_pandas()
Backlinks